正则化方法
基于模型的机器学习
选择一个模型
选择一个优化标准(目标函数)
建立一个学习算法
其中,为了让上述0/1损失函数有更好的数学性质,用一个凸的代理损失函数代替
则学习算法变为
梯度下降
选择一个初始点(),重复直到损失函数不会在任何维度减小为止:
- 选择一个方向
- 在这个方向移动一小步,以减小损失函数 (使用梯度)
问题:优化在训练集上计算,可能过拟合,最小化训练集得到的一般不会使测试集也最小。
偏差和方差
数据集和回归模型
用均方误差作为损失函数:
偏差+方差
偏差:模型预测 ( 跨数据集 ) 与目标之间的平均差异。
方差:给定点的模型方差(跨数据集)。
- 偏差-方差平衡
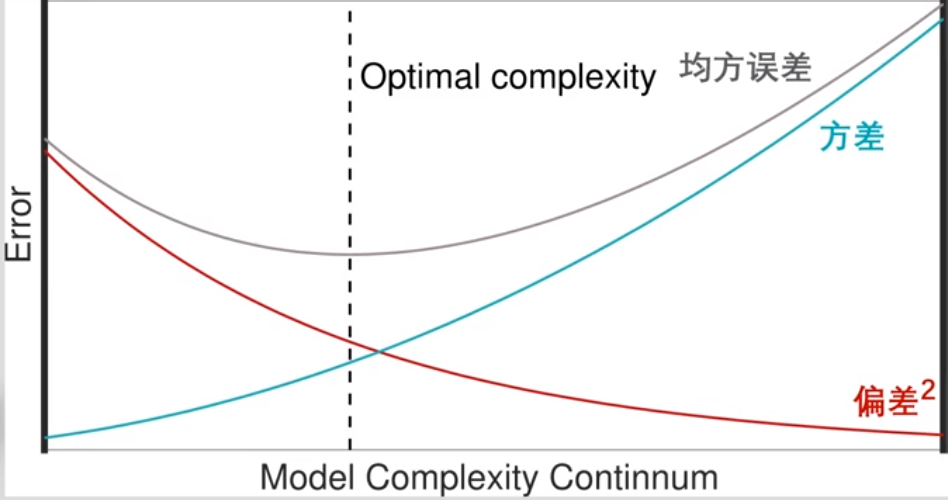
增加训练数据可以允许使用更复杂的模型,即向右移动最优复杂度。
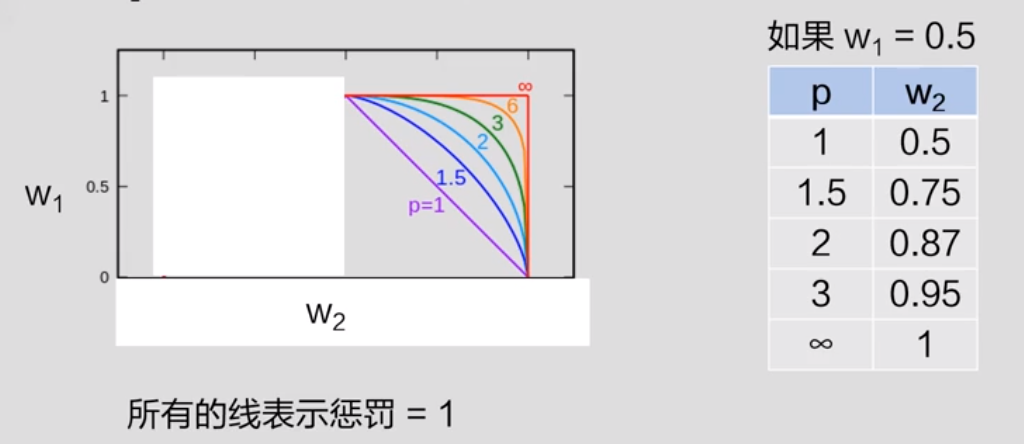
p-范数正则化
正则化项是损失函数的附加标准,以确保不会过度拟合。
对于模型,我们希望权重不宜太大;无用的特征赋予0,权重为0.
如果能确保损失函数+正则化项是凸的,可以用梯度下降。
p-范数正则:
- 正则项:1-范数
迭代
- 正则项:2-范数
迭代
如果 为正, 降低 ;如果 为负, 增加 .
- L1:
受欢迎,因为它往往导致稀疏解决方案(即大量零权重),但是,它不可导,因此仅适用于梯度下降求解法。
- L2:
受欢迎,因为对于某些损失函数,可以直接求解(不需要梯度下降,但通常仍然需要迭代求解)。
- Lp:
不太受欢迎,因为对权重缩减不够。
scikit学习包:http://scikit-learn.org/stable/modules/sgd.html
通用名称
- (普通)最小二乘:平方损失
- 岭回归:L2正则化的平方损失
- Lasso回归:L1正则化的平方损失
- 弹性(Elastic)回归:L1和L2正则化平方损失的组合
- 逻辑斯蒂回归:logistic损失